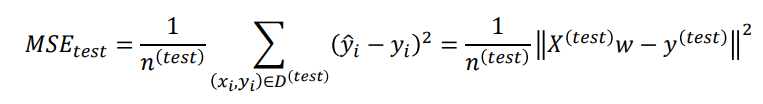Probability Plot 4가지 기본 가정 중 고정분포 가정 테스트에 이용 데이터셋이 근사적으로 주어진 분포를 따르는지에 대한 가정을 검사하기 위해 사용하는 Plot 이론상 분포에 대해 데이터를 그리고, 그림이 직선에 가까우면 데이터가 근사적으로 그 분포를 따름 직선 형태에서 멀어질수록 특정 분포의 모양과 데이터의 모양이 다르다는 뜻 ex) weibull 분포를 따르는 데이터셋 rv_weibull = stats.weibull_min.rvs(1.5, size=10000) sns.histplot(rv_weibull, bins=50, stat='density', kde=True) stats.probplot(rv_weibull, dist=stats.weibull_min, sparams=(1.5),plot=..