
1. 관계 데이터 연산의 개념
관계 데이터 연산
관계 데이터 모델을 대상으로 수행하는 연산
원하는 데이터를 얻기 위해 필요한 릴레이션 처리 방법을 명세
관계 대수와 관계 해석으로 구분
| 관계 대수 | 원하는 결과를 얻기 위해 데이터 처리과정을 순서대로 기술 |
| 관계 해석 | 원하는 결과를 얻기 위해 처리를 원하는 데이터가 무엇인지만 기술 |
데이터언어(데이터 관리시 사용되는 언어)의 유용성을 검증하는 목적으로 활용
-> 관계 대수나 관계 해석으로 명세할 수 있는 모든 질의*를 작성 가능한 데이터언어
=> 관계적으로 완전하다
* 질의(query): 데이터에 대한 처리 요구
2. 관계대수
절차언어 : 원하는 결과를 얻기 위해 릴레이션의 처리 과정을 순서대로 기술하는 언어
폐쇄 특성 : 피연산자도 릴레이션, 연산 결과도 릴레이션
릴레이션 처리 연산자 : #1. 일반집합연산자와 #2. 순수관계연산자로 분류
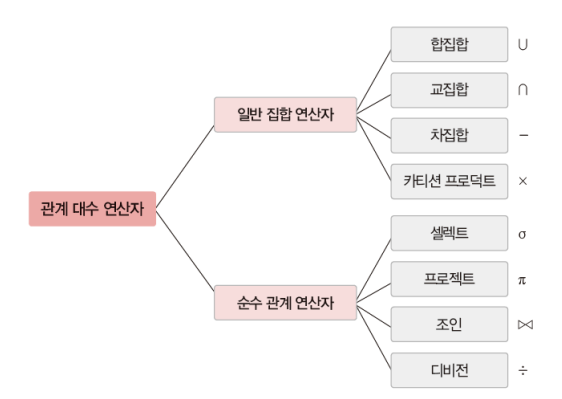
#1. 일반 집합 연산자
릴레이션이 투플의 집합이라는 개념을 이용하는 연산자

특성
1) 피연산자가 2개 필요 : 2개의 릴레이션 대상으로 연산 수행
2) 합집함, 교집합, 차집합을 수행하기위해서 피연산자로 지정되는 두 릴레이션이 합병 가능 조건을 만족시켜야함
* 합병가능조건
1) 두 릴레이션의 차수가 같아야함
= 속성의 개수가 같아야함
2) 두 릴레이션에서 서로 대응되는 속성의 도메인이 같아야함
= 자료가 저장되는 구조가 같아야함 (int, char ... )
ex1) 합병 불가능한 경우
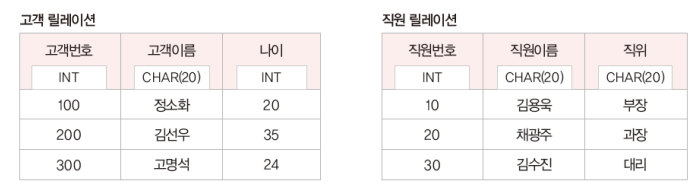
두 릴레이션의 차수(속성의 개수)는 3으로 같지만, 고객 릴레이션의 도메인은 int, char(20), int 인데 직원 릴레이션의 도메인은 int, char(20), char(20) 이라 3번째 도메인이 다르기 떄문에 합병 불가능
ex2) 합병 가능한 경우

두 릴레이션의 차수가 3으로 동일하고, 각각 릴레이션의 도메인도 int, char, int 로 동일하기 때문에 합병 가능
<일반 집합 연산자>
1. 합집합
릴레이션 R에 속하거나 릴레이션 S에 속하는 모든 투플로 결과 릴레이션 구성
합집합 결과 릴레이션의 특성
1) 차수는 릴레이션 R과 S의 차수와 같음
2) 카디널리티(투플의 개수) <= 릴레이션 R의 카디널리티 + 릴레이션 S의 카디널리티
-> 공통 카디널리티가 있는 경우 중복 삭제
3) 교환적 특징, 결합적 특징
ex)
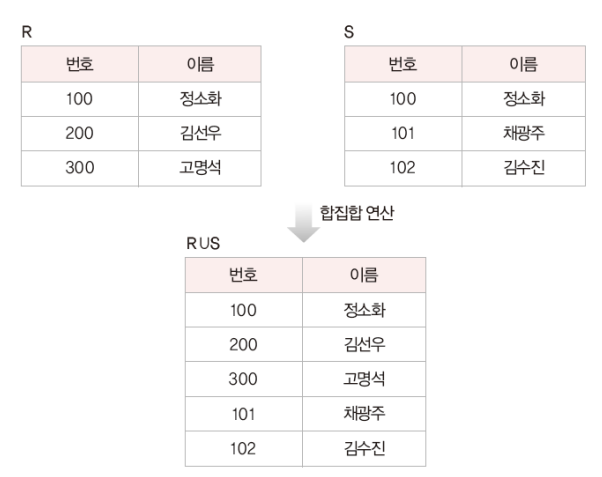
릴레이션 R과 릴레이션 S에 이름이 정소화인 카디널리티가 겹침 -> 중복을 삭제하고 합집합 연산
2. 교집합
릴레이션 R과 S에 공통으로 속하는 투플로 결과 릴레이션 구성
결과 릴레이션의 특성
1) 차수는 릴레이션 R과 S의 차수와 같음
2) 카디널리티는 릴레이션 R과 S의 어떤 카디널리티보다 크지 않음 (당연함 둘 다 가지고 있는 값만 결과값이니까)
3) 교환적 특징, 결합적 특징이 있음
ex)

3. 차집합 : R-S
릴레이션 R에는 존재하지만 릴레이션 S에는 존재하지 않는 투플로 결과 릴레이션 구성
결과 릴레이션의 특성
1) 차수는 릴레이션 R과 S의 차수와 같음
2) R-S 카디널리티 <= R 카디널리티 , S-R 카디널리티 <= S 카디널리티
3) 교환, 결합적 특징 없음
ex)
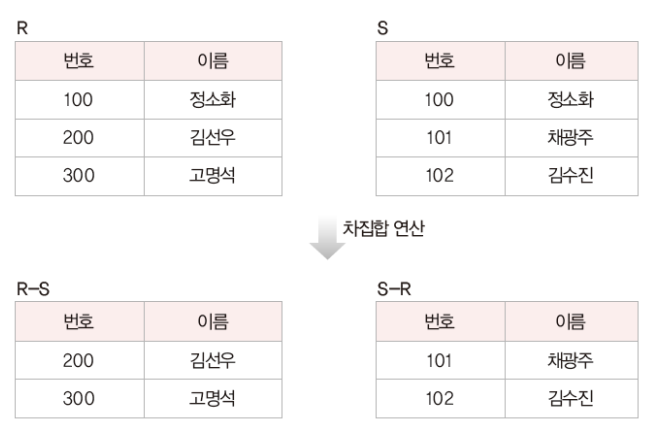
R-S 연산에서 S에도 정소화가 있으니까 결과값에서는 정소화가 빠짐
4. 카디션 프로덕트 (x)
릴레이션 R에 속한 각 투플과 릴레이션 S에 속한 각 투플을 모두 연결, 만들어진 새로운 투플로 결과 릴레이션 구성
** 곱셈같은 느낌으로 생각하면 좋다 !
결과 릴레이션의 특성
1) 차수 = 릴레이션 R의 차수 + 릴레이션 S의 차수
2) 카디널리티 = 릴레이션 R의 카디널리티 * 릴레이션 S의 카디널리티
3) 교환적 특징, 결합적 특징 있음

<순수 관계 연산자>
릴레이션의 구조와 특성을 이용하는 연산자
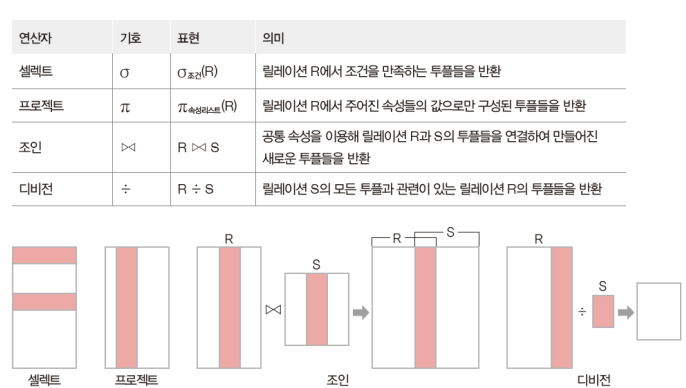
1. 셀렉트 (가로로 자른다고 생각)
릴레이션에서 조건을 만족하는 투플만 선택하여 결과 릴레이션을 구성
하나의 릴레이션을 대상으로 연산 수행

조건식은 비교식 또는 프레디킷이라고 하며, 속성과 상수의 비교 or 속성들간의 비교로 표현
비교연산자와 논리연산자 이용해 작성
ex)

1) 고객 릴레이션에서 등급이 gold 인 투플 검색

2) 고객 릴레이션에서 등급이 gold 이고, 적립금이 2000 이상인 투플 검색

교환적 특징을 가짐 : 등급을 먼저 select 하든, 적립금을 먼저 select 하든, 둘들 동시에 select 하든 결과는 동일

2. 프로젝트 (세로로 자른다고 생각)
릴레이션에서 몇개의 속성을 선택, 선택된 속성으로 구성된 릴레이션을 반환
하나의 릴레이션을 대상으로 연산 수행

ex)
1) 고객 릴레이션에서 고객이름, 등급, 적립금을 검색

2) 고객 릴레이션에서 등급 검색

3. 조인

두 릴레이션을 조합하여 결과 릴레이션을 구성
조인 속성의 값이 같은 투플만 연결, 생성된 투플을 결과 릴레이션에 포함
* 조인속성 : 두 릴레이션이 공통으로 가지고 있는 속성
1) 조인
동일 조인의 결과에서 중복되는 애트리뷰트 제거
ex)
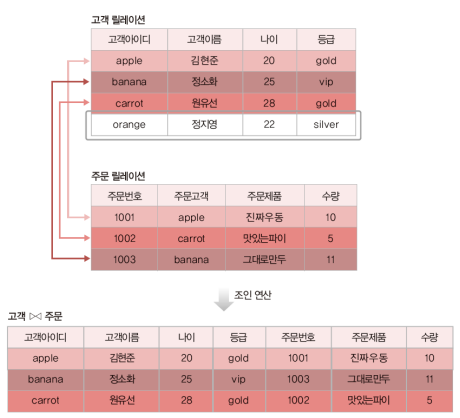
조인 속성 : 고객 아이디 (주문 고객은 주문 릴레이션의 외래키이자 고객 릴레이션의 기본 키)
ex)

공통으로 가지고 있는 속성인 B1, B2 가 조인속성
조인속성 같이 같은 투플끼리 연결
2) 자연 조인
기본적인 조인 연산, 일반적으로 조인이라 하면 자연조인을 의미

3) 세타 조인

새로운 조인 조건을 만족하는 두 릴레이션의 모든 투플을 연결, 새로운 투플로 결과 릴레이션을 구성
세타 값 : 비교연산자 (<.=<. >, >=, = ...)
결과 릴레이션의 차수 = 두 릴레이션 차수의 합
4) 동일 조인
세타 조인의 유형 중 하나, 세타값이 = 인 세타조인
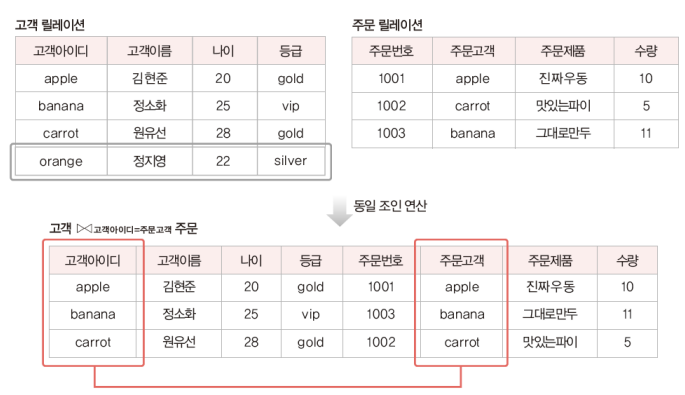
고객아이디와 주문고객의 값이 동일하더라도 제거하지 않고 전부 속성값으로 표현
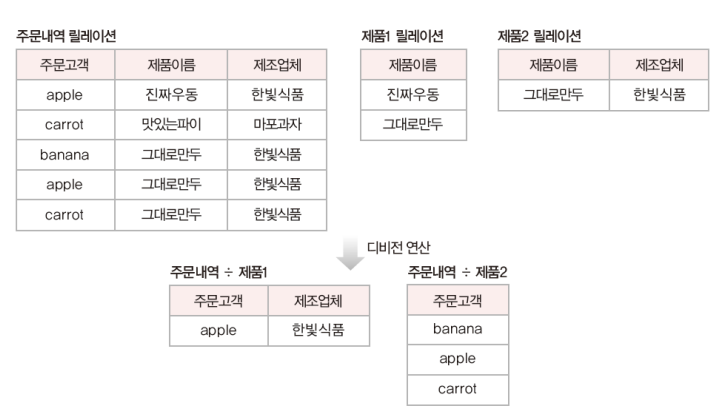
4. 디비전
분해하고 나누는 속성
ex) 12/2 = (6*2)/2 = 6

릴레이션 2의 모든 투플과 관련있는 릴레이션 1의 투플로 결과 릴레이션을 구성
릴레이션 1이 릴레이션 2의 모든 속성을 포함하고 있어야 연산이 가능
릴레이션 2의 모든 속성이 조인 속성
ex)

고객 릴레이션은 우수등급 릴레이션의 등급 속성을 포함하고 있기 때문에 연산이 가능
step1. 우수등급 릴레이션의 속성으로 고객 릴레이션을 거르고
step2. 해당 속성을 제외한 고객 릴레이션 제시
ex02)
연습문제
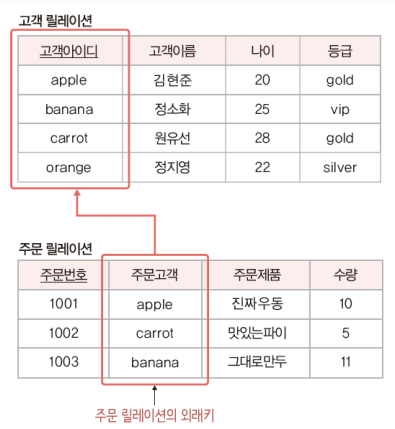
1) 등급이 gold 인 고객의 이름과 나이

2) 고객 이름이 원유선인 고객의 등급, 원유선 고객이 주문한 주문제품, 수량
주문제품과 수량은 주문 릴레이션에 있음
->고객 릴레이션과 주문 릴레이션을 조인한 릴레이션에 관계 연산자를 적용해야 함

3) 주문 수량이 10개 미만인 주문 내역 제외하고 검색
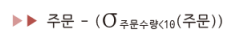
<확장된 관계 대수 연산자>
1. 세미조인

조인 속성으로 프로젝트 연산 (세로로 자르는 연산) 을 수행한 릴레이션을 이용하는 조인
step1. 릴레이션 2를 조인 속성으로 프로젝트 연산
step2. 릴레이션 1과 step1을 자연 조인하여 결과 릴레이션을 구성
불필요한 속성(조인 속성 외의 속성)을 미리 제거하여 조인 연산 비용을 줄임
교환적 특징이 없음
2. 외부조인

자연 조인 연산에서 제외되는 투플도 결과 릴레이션에 포함시키는 조인
- 두 릴레이션에 있는 모든 투플을 결과 릴레이션에 포함시킴
없는 속성에 대해서는 null 값으로 표시
ex)

1) 자연 조인 연산
고객 아이디와 주문 고객의 속성이 같으므로 고객 릴레이션의 기본키인 고객 아이디만 결과값에 포함, 주문고객 속성은 삭제됨
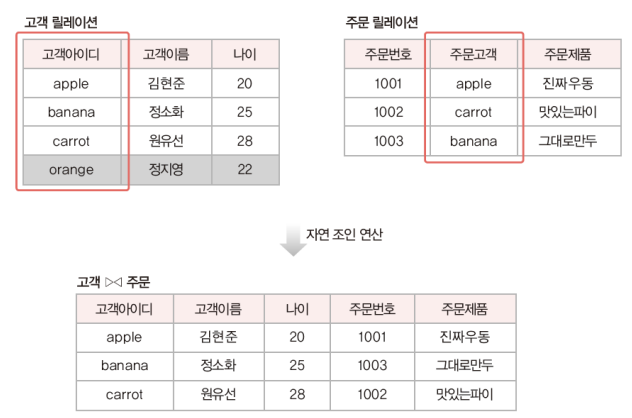
2) 세미 조인 연산
고객 릴레이션과 주문 릴레이션의 조인 속성인 고객 아이디(주문 고객)
step1. 주문 릴레이션에 주문 고객에 대해 프로젝트 연산 수행
step2. 고객 릴레이션과 step1 의 릴레이션에 대한 자연 조인 수행
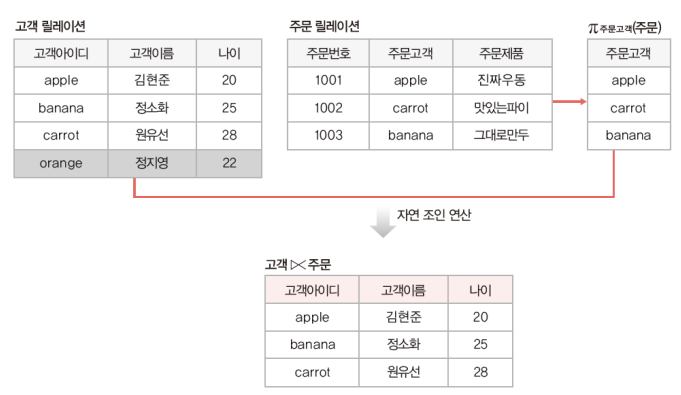
3) 외부 조인 연산
주문 릴레이션에 orange 는 없지만 두 릴레이션의 모든 투플이 결과값에 포함되므로, 없는 속성들은 null

3. 관계해석
관계 모델에서 처리를 원하는 데이터가 무엇인지만 기술하는 비절차적 언어
관계 논리라고도 부름
투플 관계 해석과 도메인 관계 해석으로 분류 가능
'School > 데이터베이스' 카테고리의 다른 글
| 데이터베이스 언어 SQL_2 (0) | 2022.06.11 |
|---|---|
| SQL-SELECT 문 (0) | 2022.04.18 |
| 관계 데이터 모델 (0) | 2022.04.16 |
| 데이터 모델링 (0) | 2022.04.15 |
| 데이터베이스 시스템 (0) | 2022.04.13 |