https://leedakyeong.tistory.com/entry/Anomaly-Detection-by-Auto-Encoder
Anomaly Detection by Auto Encoder
Auto Encoder로 Anomaly Detection 하는 방법 설명 및 Kaggle 사례 소개 오토인코더로 이상치를 탐지하는 방법에 대해 설명하기에 앞서, 이상 탐지가 무엇인지 간단히 설명하겠다. 1. Anomaly Detection이란? Norm.
leedakyeong.tistory.com
1. Anomaly Detection (이상치 탐지)
normal sample과 abnormal sample을 구별해내는 문제
2. 학습 데이터에 따른 anomaly detection의 분류
1) supervised learning
주어진 데이터셋에 정상 sample과 비정상 sample data와 각각의 label이 모두 존재하는 경우
장점 : 높은 정확도
단점 : sample 취득에 많은 시간과 비용 / class-imbalance 문제 해결 필요
class-imbalance 문제를 해결하기 위해 주로 data augmentation, loss function 재설계, 정상 data를 비정상 data 개수에 맞춰 sampling
2) semi-supervised learning
정상 sample만을 사용해서 model을 학습시키는 방식. class-imbalance 문제 해결 가능
ex. one-class SVM
정상 sample을 둘러싸는 discriminative boundary를 설정
boundary를 최대한 좁혀 boundary 밖에 있는 sample을 모두 비정상으로 간주
최대한 정상 특징을 잡아내고 특징을 벗어나면 비정상으로 판단하는 원리
장점 : 정상 sample만 있어도 학습이 가능
단점 : supervised learning 대비 정확도 떨어짐
3) unsupervised learning
label이 존재하지 않는 경우 대부분의 data를 정상 sample이라고 가정하고 학습시키는 방식
ex. autoencoder
장점 : labeling 과정이 필요하지 않음
단점 : hyperparameter에 매우 민감, 양/불 판정 정확도가 높지 않음
3. 비정상 sample 정의 방식에 따른 분류
1) novelty detection
분류상 normal class에 속하긴 하지만 model이 학습과정에서 한번도 본 적 없는 sample
2) outlier detection
normal class에 속하지 않는 sample을 찾아내는 방법
4. AutoEncoder
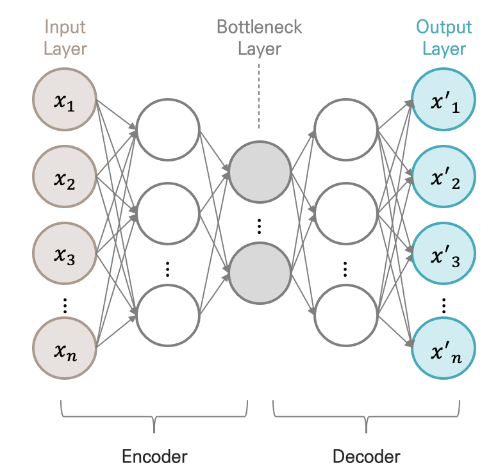
입력과 출력층의 뉴런 수가 동일한 신경망 모델
loss function : MSE (입력과 출력의 차이) -> 입력과 출력이 동일해지도록 학습
저차원의 hidden layer가 입력과 같은 출력을 내기 위해 학습하는 과정에서 입력 데이터의 가장 중요한 특성 (feature) 학습
hyperparameter : hidden layer의 dimension -> 몇개의 뉴런으로 할지, 몇층을 쌓을지는 성능과 목적에 따라 지정
Encoder : input layer ~ bottleneck layer, 입력을 내부 표현으로 변환하는 과정, 오토인코더 전체를 학습시킨 후 encoder만 차원축소에 이용하기도 함
Decoder : bottleneck layer ~ output layer, 내부 표현을 출력으로 변환하는 과정
Bottleneck layer = latent variable, latent feature, hiddne representation
5. Anomaly Detection by AutoEncoder
오토인코더의 특성은 입력 데이터의 가장 중요한 특징을 학습하는 것
noise가 아닌 주요 특징에 대해서만 학습하게 됨

normal sample은 input과 output 간 차이 거의 없음
abnormal sample은 비정상적인 부분이 noise로 인식, noise가 제외된 정상 sample과 비슷한 output이 나오게 되면서 output과 input의 차이가 커짐 (output은 중요한 부분만 학습하니까 정상에 가까운 output이 나옴)
=> 비정상 sample은 정상 sample에 비해 MSE가 커짐
'Deep Learning' 카테고리의 다른 글
| lambda(), sort()에서 key와 lambda 사용하기 (0) | 2022.08.18 |
|---|---|
| os와 glob (0) | 2022.08.18 |
| PyTorch : Dataset과 DataLoader (0) | 2022.08.16 |
| PyTorch : class와 nn.Module 이용해서 신경망 모델 정의 (0) | 2022.08.16 |
| PCA (0) | 2022.08.16 |